




您可以使用以下 SQL 语句删除 MS SQL Server 表中重复的行:
您需要将 tablename 替换为要删除重复行的表名,并将 column1, column2,... columnN 替换为用于检查重复的列名。该语句使用 ROWNUMBER()函数和 PARTITION BY 子句来标识重复的行,然后使用 DELETE 语句删除其中一个副本。
这样说有些抽象,下面举一个例子:
比如我有一个deadUrlRecordcopy1表,存的数据如下格式。
这个表存在一个问题,url列有一部分是重复的。用group by语句可以查出来,有挺多重复的,那么,如何删除多余的数据,只保留一条呢?
这就要采用文章开头给出的语句了。
WITH cte AS ( SELECT url, ROWNUMBER() OVER (PARTITION BY url ORDER BY url) AS rn FROM deadUrlRecordcopy1 WHERE status =NotFound)DELETE FROM cte WHERE rn >1;
乍一看一脸懵逼,但是执行发现竟然成功删除了重复数据,达到了预期效果,为什么呢?
这要解释下这一行代码:
ROWNUMBER() OVER (PARTITION BY url ORDER BY url) AS rn
这是一种 SQL 语法,用于对一个查询结果集的行进行编号,并且可以根据特定列来分组编号。
具体来说,ROWNUMBER()是一个窗口函数,它会为查询结果集中每一行计算一个行号。而 OVER 子句则是指定如何定义窗口(window),也就是要给哪些行计算行号。在这个例子中,PARTITION BY url 表示按照 url 这一列进行分组,也就是说对于每个不同的 url 分别计算行号;ORDER BY url 则表示按照 url 这一列进行排序,这样同一个 url 中的行就会按照 url 的值依次排列。最后,AS rn 则是给这个新的行号列起个名字,即 rn。
例如,假设有如下表格:
如果执行以下 SQL 查询:
SELECT id, url, ROWNUMBER() OVER (PARTITION BY url ORDER BY url) AS rn FROM mytable;
则会得到以下结果:
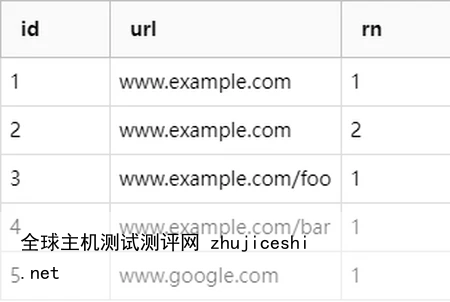
其中,同一个 url 中的行拥有相同的行号,同时这个行号是按照 url 的值进行排序的。
然后执行刚才那段代码的片段试一下,可能更好理解:
url不同的,行号都是1。相同的,会从1开始排序,所有就出现了2.
然后用 DELETE FROM cte WHERE rn >1;删除行号>1的数据,就成功把多余的数据删除了,非常巧妙。

0 留言