




大数据时代的数据特点
一般认为,大数据主要具有 四方面的典型特征——规模性(Volume)、多样性(Variety)、高速性(Velocity)和价值性(Value), 即所谓的"4V
(1)规模性,即大数据具有相当的规模,其数据量非常巨大。淘宝网近4亿的会员每天产生的商品交易数据约20TB, Facebook (脸书)约10亿的用户每天产生的日志数据超过300TB。数据 的数量级别可划分为B、KB、MB、GB、TB、PB、EB、ZB等,而数据的数量级别为PB级别的 才能称得上是大数据。根据IDC公司的最新研究,未来10年,全球的数据总量将会增长50倍, 以此推算,数据产生的速度越来越快,而且数据总量将呈现指数型的爆炸式增长。
(2) 多样性,即大数据的数据类型呈现多样性。数据类型繁多,不仅包括结构化数据,还包 括非结构化数据和半结构化数据。其中,结构化数据即音频、图片、文本、视频、网络日志、地理 位置信息等。传统的数据处理对象基本上都是结构化数据,而在现实中非结构化数据也是大量存在 的,所以既要分析结构化数据又要分析非结构化数据才能满足人们对数据处理的要求。
(3) 高速性,即处理大数据的速度越来越快,处理时要求具有时效性,因为数据和信息更新 速度非常快,信息价值存在的时间非常短,必须要求在极短的时间下在海量规模的大数据中摒除无 用的信息来搜集具有价值和能够利用的信息。所以随着大数据时代的到来,搜集和提取具有价值的 数据和信息必须要求高效性和短时性。
(4) 价值性。从大数据的表面数据进行分析,进而得到大数据背后重要的有价值的信息,最 后可以精确地理解数据背后所隐藏的现实意义。
大数据的价值密度的高低与数据总量的大小成反比。以视频为例,一部1小时的视频,在连 续不间断的监控中,有用数据可能仅有一两秒。如何通过强大的机器算法更迅速地完成数据的价值 提纯成为目前大数据背景下亟待解决的难题。
大数据时代的关键技术
(1) 大数据釆集技术
大数据釆集是指通过对社交网络交互数据、移动互联网数据、RFID射频数据以及传感器数据 的收集,获得各种类型的结构化、半结构化(或称之为弱结构化)及非结构化的海量数据。大数据 釆集是大数据知识服务模型的根本。重点要突破分布式、高速、高可靠数据爬取等大数据釆集技术。
(2) 大数据预处理技术
大数据预处理技术主要完成对已接收数据的抽取、清洗等操作。因获取的数据可能具有多种 结构和类型,数据抽取能帮助我们从各种异构的源数据源系统抽取到目的数据源系统需要的数据。 大数据并不全是有价值的,有些数据并不是我们所关心的内容,而另一些数据则是完全错误的干扰 项,因此要对数据进行过滤去噪,从而提取出有效数据。
(3) 大数据存储及管理技术
大数据存储与管理要用存储器把釆集到的数据存储起来,并进行管理和调用。重点解决复杂 结构化、半结构化和非结构化大数据存储管理技术。主要解决大数据的可存储、可靠性及有效传输 等几个关键问题。可靠的分布式文件系统(DFS)是高效低成本的大数据存储技术。
(4) 大数据分析及挖掘技术
大数据挖掘就是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中提取隐含 在其中的、人们事先不知道的但又是潜在有用的信息和知识的过程。大数据挖掘根据挖掘方法可粗 略地分为机器学习方法、统计方法、神经网络方法和数据库的多维数据分析方法等,它能够将隐藏 于海量数据中的信息和知识挖掘出来。
(5) 大数据可视化展现技术
大数据可视化无论对于普通用户或是数据分析专家都是最基本的功能。大数据可视化可以让 数据自己说话,让用户直观地感受到结果,也可以让数据分析师根据图像化分析的结果做出一些前 瞻性判断。
大数据案例:
塔吉特超市精准营销案例
美国明尼苏达州一家塔吉特超市门店被客户投诉,一位中年男子指控塔吉特将婴儿产品优惠 券寄给他的女儿(一个高中生)。但没过多久他却来电道歉,因为女儿经他逼问后坦承自己真的怀 孕了。
原来孕妇对零售商来说是一个含金量很高的顾客群体,塔吉特百货就是靠着分析用户所有的 购物数据,然后通过相关关系分析得出事情的真实状况。在美国,出生记录是公开的,等孩子出生 了,新生儿母亲就会被铺天盖地的产品优惠广告包围,那时再行动就晚了,因此必须赶在孕妇怀孕 前期就行动起来。塔吉特的顾客数据分析部门发现,怀孕的妇女一般在怀孕第三个月的时候会购买 很多无香乳液。几个月后,她们会购买镁、钙、锌等营养补充剂。根据数据分析部门提供的模型, 塔吉特制订了全新的广告营销方案,在孕期的每个阶段给客户寄送相应的优惠券。结果,孕期用品 销售呈现了爆炸性的增长。塔吉特的销售额暴增,大数据的巨大威力轰动了全美。
这个案例说明大数据在精准营销上的成功,利用大数据技术分析客户消费习惯,了解其消费 需求,达到精确营销的目的。这种营销方式的关键在于时机的把握上,要正好在客户有相关需求时 才进行营销活动的精准推送,这样才能保证较高的成功率。
某运营商大数据平台案例
众所周知,用户的上网行为中蕴含着大量的客户特征和客户需求信息,这些信息至关重要, 而又是传统的CDR话单分析所不能提供的。因此,这就要求用户的上网日志记录必须被保存,而 且需要进行数据分析挖掘处理,然后根据处理结果定义用户的行为习惯,为运营商业务部门提供重 要的营销依据。上网数据是一个典型的大数据。釆用什么方式进行存储和检索是一个大问题,此前 运营商采用的架构方式是IOE的架构,但是它解决不了我们的问题。存储这么大规模量的数据, 以后超越了可管理容量的上限。在做査询的时候,关系型数据库对大规模数据做操作的时候性能是 严重下降的。
传统IOE方式用来存储这么大的上网记录已经不可能了,需要釆用大数据技术Hadoop来解决。 Hadoop本身的底层核心组件之一是分布式文件系统HDFS,可以解决海量数据如何存储的问题。 另外一个核心组件MapReduce计算框架解决了海量数据如何计算的问题。此外,构建于HDFS之 上的HBase分布式数据库处理海量数据的入库速度和检索速度非常迅速。目前运营商已构建了一 个全国集中的一级架构海量数据存储和査询系统,在集团公司范围内进行统一部署,各个省份仅仅 是做数据的釆集,按照业务实时性将数据传送到集团公司,由集团公司统一处理,全国所有用户所 有上网记录数据都放北京数据中心里。截至目前已经部署了 4.5PB的存储空间,分布在300个数据 节点上,系统每天有能力处理700亿条上网记录。
Hadoop概述和介绍
Hadoop发展历史和应用现状
Hadoop最初是开始于2002年的Apache的Nutch项目。Notch是一个开源Java实现的搜索引 擎,它遇到的难题是,在抓取Web数据时如何保存和使用这些庞大的数据。随后Google在2003 年发表了一篇技术学术论文谷歌文件系统(GFS, Google File System,是Google公司为了存储海 量搜索数据而设计的专用文件系统)。2004年Nutch创始人Doug Cutting模仿Google的GFS论文 实现了分布式文件存储系统NDFSo
2004年Google又发表了一篇技术学术论文MapReduce (一种分布式编程模型,用于大规模数 据集的并行分析运算)。
2005年Doug Cutting基于MapReduce的思想,在Nutch搜索引擎实现了 该功能。2006 年,Yahoo 邀请 Doug Cutting 加盟,Doug Cutting 将 NDFS 和 MapReduce 升级命名 为Hadoopo
2008年1月,Hadoop正式成为Apache的顶级项目,开始被雅虎之外的其他公司使用。 2009年,Yahoo使用4000节点的机群运行Hadoop,支持广告系统和Web搜索的研究。Facebook 的Hadoop机群扩展到数千个节点,用于存储内部日志数据,支持其上的数据分析和机器学习。淘 宝的Hadoop系统达到千台规模,用于存储并处理电子商务的交易相关数据。
Hadoop改变了企业对数据的存储、处理和分析的过程,加速了大数据的发展,形成了自己非 常火爆的技术生态圈,成为事实上的大数据处理标准。
Hadoop 的特点
Hadoop是一个能够对大规模数据进行分布式处理的基础框架,用户可以在不了解分布式底层 细节的情况下开发分布式程序,并充分利用集群的威力进行计算和存储。它具有如下特点:
(1) 低成本:可以通过普通机器组成的服务器集群来分发以及处理数据。
(2) 高可扩展性:集群可以很容易扩展到数千个计算机节点。
(3) 高效率:Hadoop釆用分布式存储和分布式计算处理两大核心技术,通过分发数据,在 数据所在的节点上并行地高效处理它们。
(4) 高可靠性:Hadoop能自动地维护数据的多份复制,并且在任务失败后能自动地重新部 署计算任务。
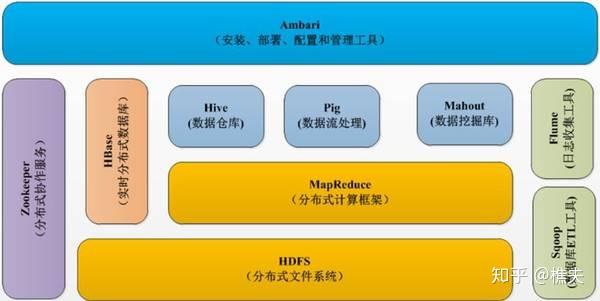
Hadoop的生态系统
早期的Hadoop (包括Hadoop vl.O以及更早之前的版本)
主要由两个核心组件构成:HDFS 和MapReduce。
HDFS分布式文件系统是Google GFS的开源版本,
MapReduce分布式计算 框架实现了由Google工程师提出的MapReduce编程模型。
还有一些围绕在Hadoop周围的开源项 目,为完善大数据处理的全生命周期提供了必要的配套和补充。这些软件常用的有ZooKeeper (分 布式协调服务)、Hive (基于Hadoop的数据仓库工具)、HBase (实时分布式数据库)、Pig (数 据流语言和运行环境)、Flume (日志釆集工具)、Sqoop (Hadoop和关系数据库导入导出工具)、 Mahout (数据挖掘工具)等
Cloudera是Hadoop领域知名的公司和市场领导者,提供了市场上第一个Hadoop商业发行版 本。在多个创新工具的贡献者排行榜中名列榜首。它的系统管控平台ClouderaManager非常容易使 用,界面清晰,是监控和部署大数据集群的最佳平台。Cloudera除了提供免费版本(拥有核心管理 监控功能和群集节点数目无限制)的下载,还为付费客户提供功能增强企业版本。企业版提供在企 业生产环境中运行Hadoop所必需的运维功能,如无宕机滚动升级、灾备、数据治理审计等。
现在主流的公有云都已经在原有提供虚拟机的laaS服务之外提供了基于Hadoop的PaaS云计 算服务,未来这块市场的发展将超过私有Hadoop的部署。
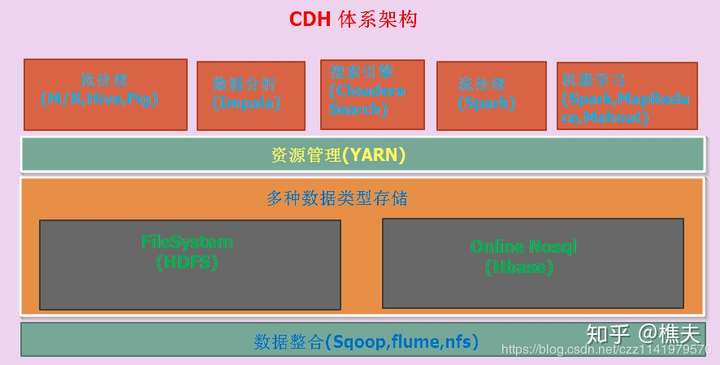
Cloudera 的 Hadoop 发行版 CDH 简介
Cloudera提供了 Hadoop的商业发行版CDH,能够十分方便地对Hadoop集群进行安装、部署 和管理。如图2-1所示,CDH是Cloudera发布的一个自己封装的Hadoop商业版软件发行包,里 面不仅包含了 Cloudera的商业版Hadoop,同时CDH中也包含了各类常用的开源数据处理与存储框架,如 Spark,Hive,HBase 等
该部分介绍详见 Cloudera大数据平台简介—官方版.pdf
http://115.159.217.198/Cloudera大数据平台简介—官方版.pdf
大数据运维的挑战
能力三核模型分析

0 留言